SERVICES
Softberry works in close contact with its clients and collaborators to meet all their computational genomics needs. Our team of researchers and software developers is able to solve most complex problems related to our area of expertise. The follwoing is the list of some services we perform for pharmaceutical and biotech companies.
Genome Annotation
We provide custom genome annotation services using our unique set of genome analysis tools. Typical annotation process involves the following steps:
- Train parameters of gene-prediction programs on known genes of given organisms
- Whenever practical, learning set is expanded to include genes of related organisms
- Train and test parameters and select those optimal for the organism under analysis
- Predict genes
- Find exons similar to known proteins and ESTs and use this information to improve the accuracy of ab-initio gene prediction
- Use our genome comparison tool to find conserved regulatory regions and further improve gene identification using sequences of related organisms
- Define secondary strucure, functional site signature and cell location of predicted proteins:
Genome annotation programs:
-
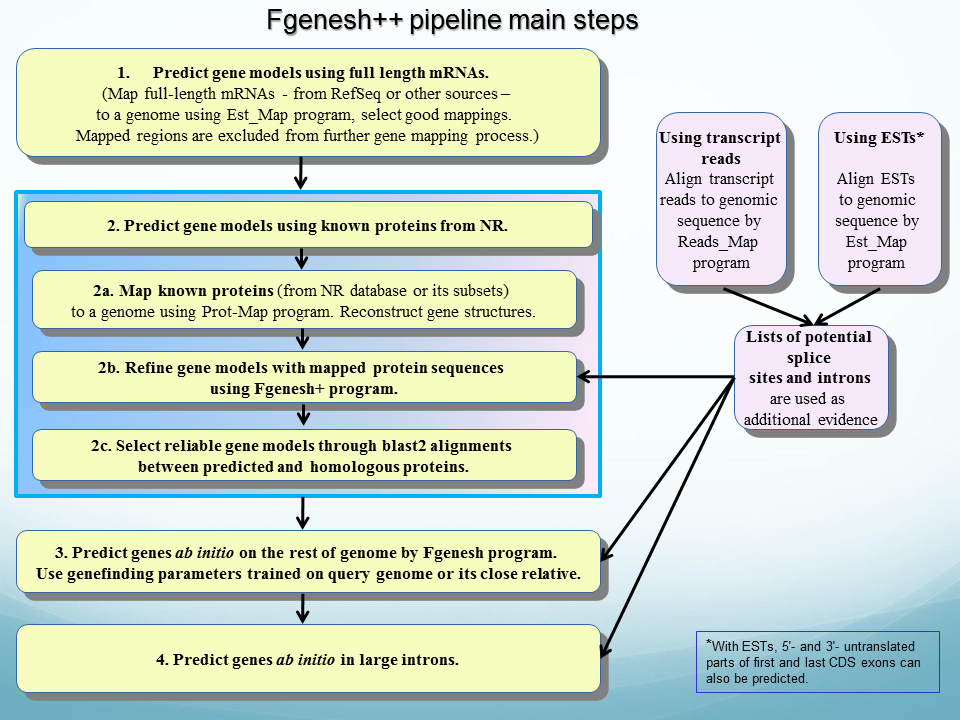
Eukaryotic genome annotation pipeline Fgenesh++ (see flowchart) that includes the following steps:
-
a) Mapping known genes/mRNAs from RefSeq or other sources (EST_Map program);
-
b) Mapping known proteins (typically from NR database) to a genome;
-
c) Identification of splice sites by mapping a set of known ESTs or NGS RNASeq reads;
-
d) Identification of gene models that involve alternative splicing.
See examples in Sequence annotation explorer.
-
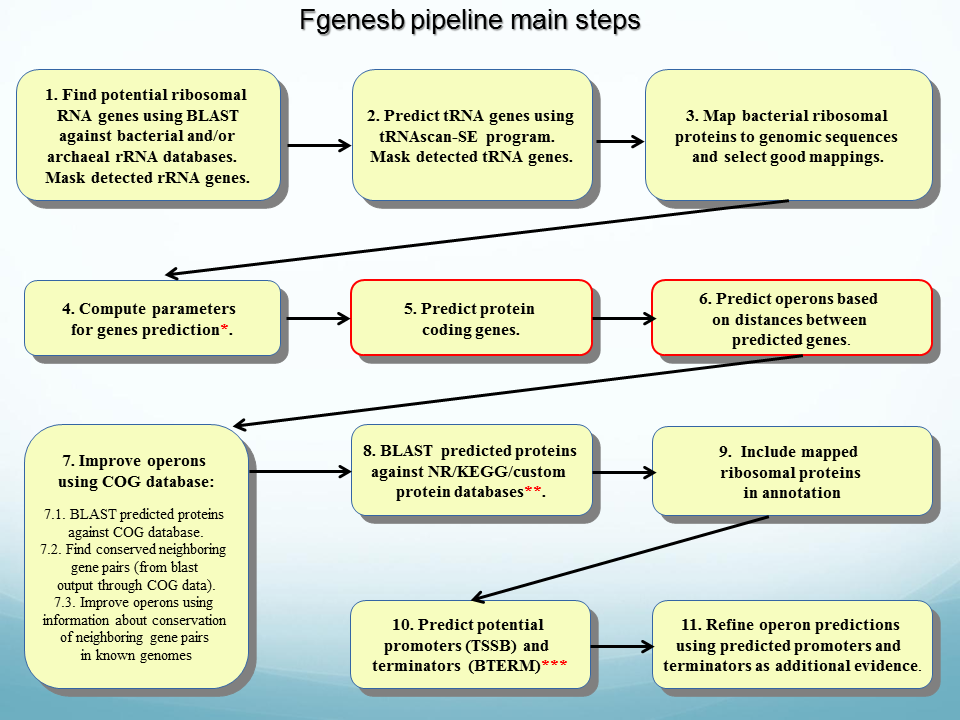
Bacterial genome annotation pipeline Fgenesb ( see flowchart) predicts genes (including RNA genes), operons, promoters and terminators. It provides functional and pathway annotation of predicted proteins with the user selected databases such as NR, COGS, EggNOG, KEGG and etc.
-
Eukaryotic and Bacterial genes and functional sites identification and genome annotation:
-
Fgenesh: the fastest ab initio HMM-based eukaryotic
gene prediction program with parameters for
506 genomes.
-
Other programs of FGENESH suite include
FGENESH-2,
FGENESH+ and
FGENESH_C,
which perform genefinding with support of related genomic, or protein or cDNA sequence, respectively, programs for Best ORF and splice sites, non-standard splice sites identification.
-
BESTORF - finding potential coding fragment EST/mRNA
-
FSPLICE - finding splice sites in genomic DNA
-
FEX - finding potential 5'-, internal and 3'-coding exons
-
BPROM - prediction of bacterial promoters
-
FindTerm - Finding Terminators in bacterial genomes
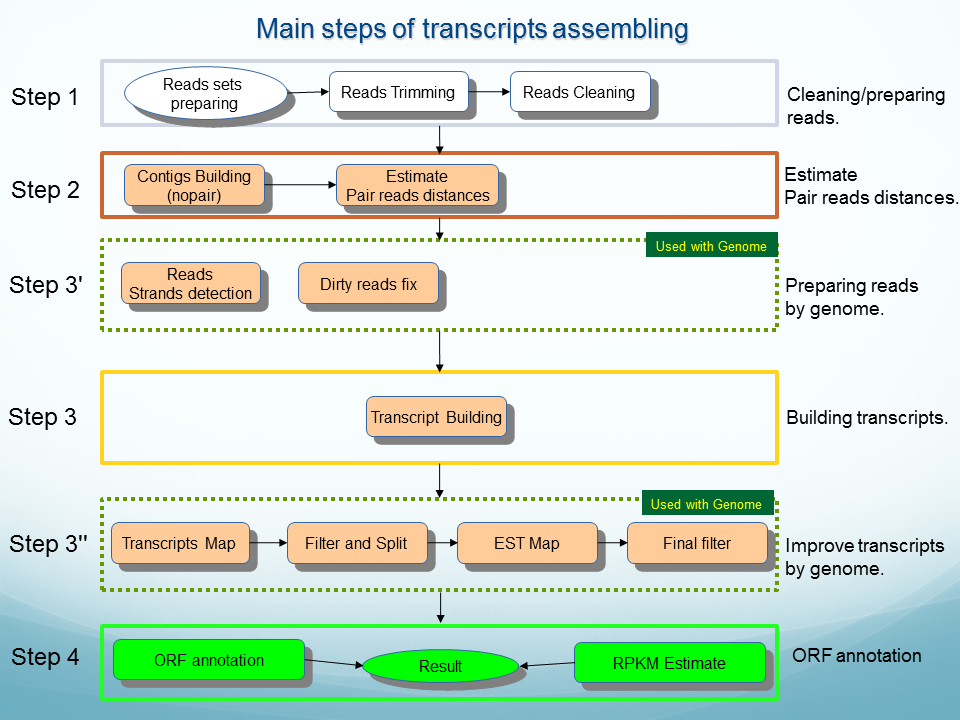
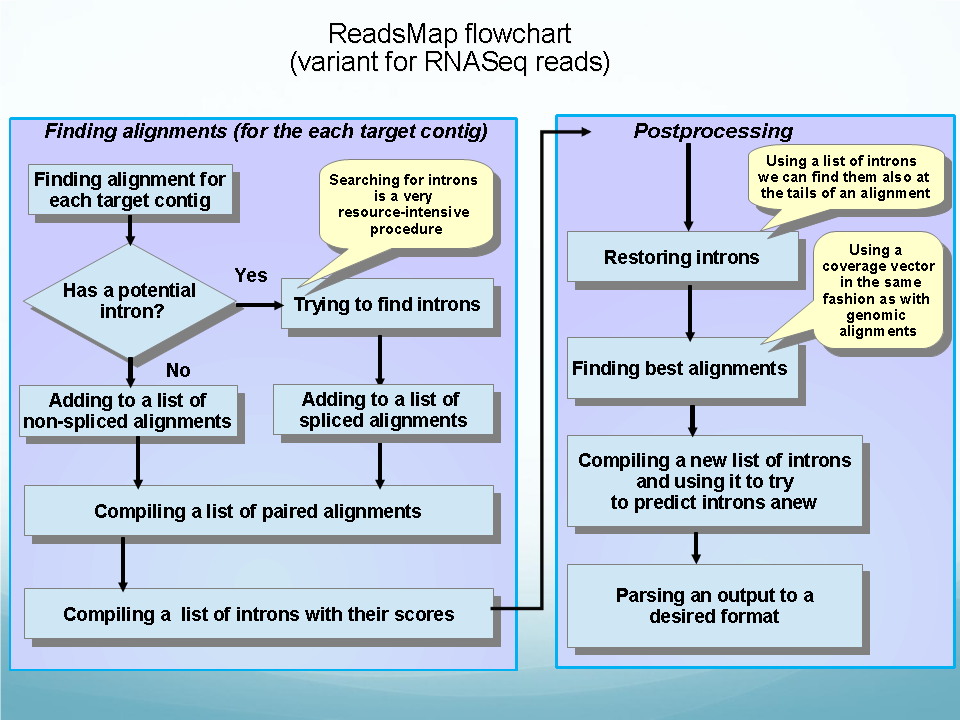
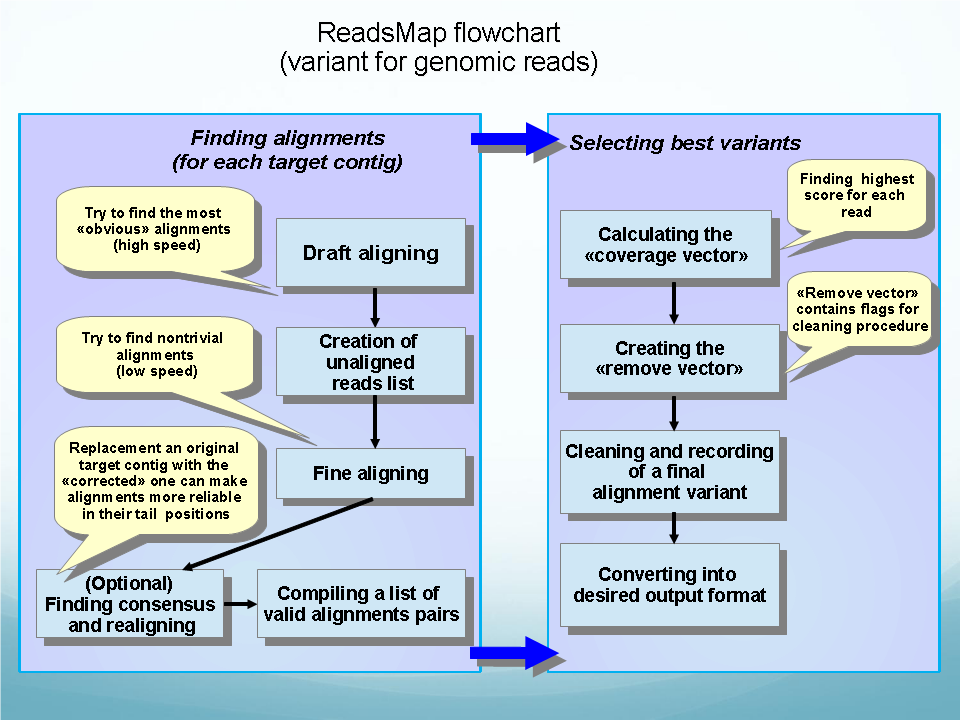
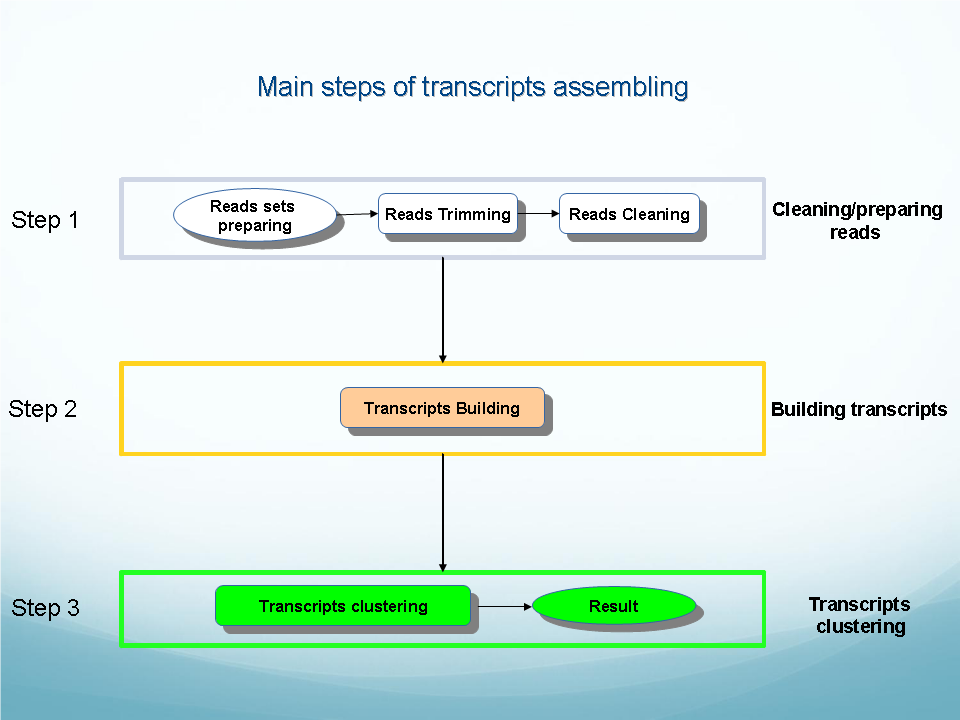
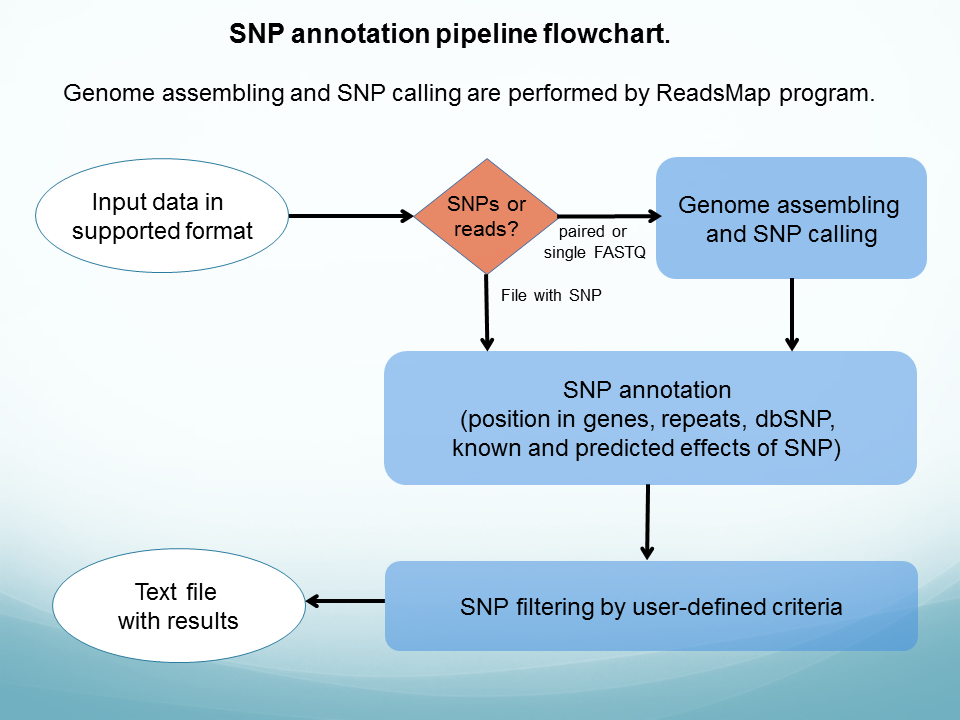
Analysis of NGS data: genome and transcriptome assembling, reads mapping, SNP discovery and evaluation:
Promoter and functional sites prediction:
-
TSSW/
TSSP/
TSSB: Programs for predicting animal, plant and bacterial promoters and functional sites.
-
RegSite: Database of gene regulatory elements.
-
Nsite/
NsiteM/
NsiteH: programs for analysis of regulatory regions and composition of their functional motifs. .
-
POLYAH: - Recognition of 3'-end cleavage and polyadenilation region
-
PATTERN,
ScanWM-PL : search for patterns.
-
CpGFinder: GC-islands finding .
Database search, genome comparison and Protein/RNA/EST/ mapping to genome programs
-
PROT_MAP: mapping of a set of proteins on genome.
-
EST_map: Mapping your mRNA/EST to Chromosome sequence of Human genome
-
SMAP: mapping oligonucleotides to genome.
-
DBSCAN :database homology search program similar to BLAST, but handling multimegabyte-size sequences.
Protein function and structure prediction and analysis
-
ProtComp: Program for predicting protein sub-cellular location, works on all taxons, including animals, plants, fungi and bacteria.
-
PDISORDER: Protein Disorder Prediction.
-
CYS_REC,
PSSFinder,
SSP
NNSSP
SSPRED
SSENVID
SSPAL:
programs of secondary structure prediction.
-
HMod3DMM: energy minimization program by molecular mechanic.
-
3DmodelFit: program for comparison protein 3D model and its original structure.
-
MDynSB: Optimization of a protein structure via MD simulation in an implicit water solvent, optimization and folding of a protein via (the user defined) simulated annealing protocol in an implicit water solvent, optimization of a predefined protein loops while non-loop parts of the protein molecule is kept fixed in the course of the loop optimization.
-
3D-Match, 3D-MatchDB and etc: Programs for protein structure comparison, prediction and analysis.
See examples in 3D-explorer.
Alignment genome sequences, synteny reconstruction
RNA structure computing
Seqman - manipulation with sequences
MolQuest
MolQuest: Comprehensive, easy to use desktop application for sequence analysis. Includes ~ 100 program modules, dozen viewers and GUI running on Window, Linux and Mac OS platforms.
See
www.molquest.com for details.
Training parameters of gene-prediction programs
We develop for our clients custom-made data sets for gene- or functional site-prediction programs. These data sets can include known genes of given organisms, genes of related organisms, subsets of genes with particular expression patterns and other considerations.
Expression data analysis
Our GeneExplorer program reads and analyzes expression data represented by relative intensities of signals for different types of gene expression experiments. It can analyze all or marked groups of genes or tissues, select tissue-specific genes based on complex criteria, provide visual represenation of expression data, identify genes correlatively expressed in a given set of tissues, select disease-specific genes with particular characteristics, such as receptors or secreted proteins.
See also SelTag - a tool for analysis of expression data and Proteomics - MS data processing.
Customizing our software
We customize our software to meet needs of our clients: support of different computer platforms, modification of data formats for easy integration into customers' databases, development of databases with specific information compiled from public sources or computed from avaiable informaton. In addition, almost all our software is available with source codes, and therefore can be easily changed by customers themselves.
Custom Software Development
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}